无锁并发对象
在多线程共享内存并发场景,程序员需要注意控制不同线程访问同一内存单元的顺序,否则可能产生“数据竞争”。一般语言通过提供互斥锁等特性来支持进程并发的访问共享内存。
然而让程序员自己来控制线程访问共享内存仍然是一件复杂且并发性能不高的事情:
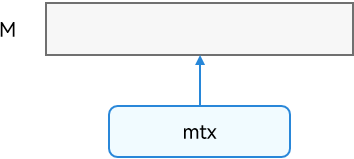
例如上图,一块内存 M 多线程共享,用一个互斥锁同步对内存块 M 并发访问,开发效率、运行性能都不是最优。
那么是否能对内存 M 进行切分,以更细粒度的方式来加锁以提升性能,并且语言自动实现锁的保护而让开发者像单线程一样编写程序呢?
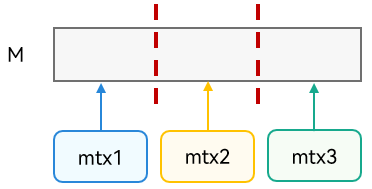
如下图:展示了细粒度并发控制,将内存块 M 划分为多个区域,不同线程可以并发访问不同区域。但细粒度并发算法复杂,并且在实际场景中,M 可能代表一个数据结构,对本就复杂的数据结构做细粒度的并发控制并不容易,很容易产生“数据竞争”或“不具有并发原子性”等并发问题。
为了解决该问题,仓颉提供了基于细粒度并发算法实现的并发对象,而用户通过调用并发对象的接口来操作多线程共享内存,从而实现:
- 为用户提供无锁编程体验:用户通过接口调用实现高效的共享内存并发访问。
- 为用户提供并发安全保障:仓颉并发对象的接口可保证无数据竞争,核心接口具有并发原子性。
- 提升性能:仓颉并发对象的设计使用细粒度并发算法。
- 保证并发原子性:仓颉并发对象的核心方法具有并发“原子性”,即从用户视角来看,该方法调用执行不会被其它线程打断。
下表展示了仓颉提供的多线程共享并发对象,并提供并发安全和并发性能的保障: | 类型 | 数据结构 | | ---- | ---- | | 原子整数类型 | AtomicInt8、AtomicInt16、AtomicInt32、AtomicInt64、AtomicUInt8、AtomicUInt16、AtomicUInt32、AtomicUInt64 | | 原子布尔类型 | AtomicBool | | 原子引用类型 | AtomicReference、AtomicOptionReference | | 并发哈希表 | ConcurrentHashMap | | 并发队列 | BlockingQueue、ArrayBlockingQueue、NonBlockingQueue |
1.并发安全: 用户在并发场景调用原子类型和并发数据结构接口操作多线程共享对象不会产生“数据竞争”。原子类型为用户提供了并发场景下:整型、布尔型和引用类型的原子操作。并发数据结构的核心方法具有并发原子性,例如:ConcurrentHashMap 中的插入键值对 put,删除键值对 remove 和替换键值对 replace 等方法。并发场景下,用户可以将这些操作的调用执行视为原子的,不会被其它线程打断。
2.提升并发性能:
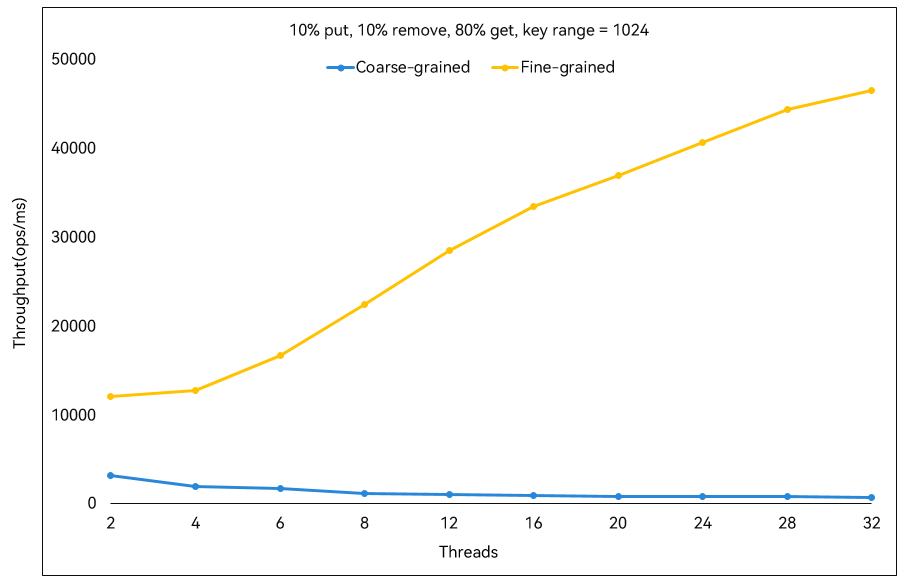
并发哈希表和并发队列基于上述介绍的细粒度并发算法实现,下图展示了仓颉并发哈希表 ConcurrentHashMap 与使用一把互斥锁控制多线程并发访问 HashMap(粗粒度并发控制)的性能对比,其中,横坐标为线程数,纵坐标为每毫秒完成的并发哈希表操作数(并发哈希表操作中,put、remove 和 get 方法分别占 10%、10%、80%)。黄色线条为仓颉 ConcurrentHashMap 的测试数据,而蓝色线条则为粗粒度方法的测试数据,可见使用细粒度并发算法的仓颉并发哈希表性能相比粗粒度方法优势明显,且性能随着线程数的增加而提升。
下图是仓颉并发队列 BlockingQueue 在 single-producer & single-consumer 场景下与使用一把互斥锁控制多线程并发访问队列(粗粒度并发控制)的性能对比,我们分别测试了队列容量为 128 和 4096 的场景,纵坐标为每毫秒出入队元素的个数,仓颉 BlockingQueue 性能相比粗粒度方法优势明显。
