全并发整理 GC
仓颉提供全并发(fully concurrent)的内存标记整理 GC 算法作为其自动内存管理技术的底座,具有延迟极低、内存碎片率极低、内存利用率高的优势。
消减 GC 暂停时间
在有些时延敏感的重要场景里,STW GC 或近似并发 GC 难以满足技术规格。比如移动场景高达 120Hz 的屏幕刷新率(预计后续会更高)要求绘制一帧的总体耗时小于 8ms,毫秒级的 GC 暂停可能成为主要的时延因素。在千级乃至万级的高并发场景里,近似并发算法需要在单次 STW 里完成上千个调用栈的扫描,这个量级的扫栈操作可能使得 STW 的时间延长到超过十毫秒。
相比于现有的 STW GC 以及 mostly concurrent GC(参考下图), 仓颉的全并发 GC 摒弃了 STW 作为 GC 同步机制,采用了时延更短的轻量同步机制,其应用线程完成 GC 同步的平均耗时小于百微秒,典型情况下数十微秒即可完成 GC 同步。
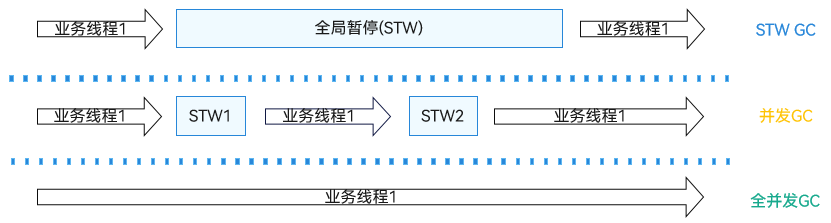
能实现如此高效的 GC 同步主要基于以下两点关键要素:
- 安全点
并发 GC 需要处理 GC 线程与应用线程之间的状态同步关系。“安全点”机制是 GC 线程用于控制应用线程实现 GC 状态同步的技术手段。“安全点”机制包括两个组成部分:一是由编译器在编译仓颉代码时插入的安全点检查代码,一般插在必经路径上,比如函数头或尾,循环回边等处;二是 GC 算法中实现的安全点同步逻辑。当 GC 线程需要把 GC 状态同步到特定应用线程时,GC 线程先激活该应用线程的安全点检查,后续当该应用线程执行到安全点检查代码时,看到自身的安全点处于激活状态,就会响应 GC 的同步请求,改变自身的 GC 状态至指定状态。通过安全点机制,GC 线程可以控制应用线程的 GC 状态变更,配合内存屏障,让并发 GC 得以正确执行。不同的 GC 状态需要相应的内存屏障配合。
- 内存屏障
仓颉语言实现的全并发 GC 还需要正确处理三类数据竞争关系: (1) GC 线程与应用线程之间的数据竞争关系。 (2) GC 线程之间的数据竞争关系。 (3) 由于应用线程分担了部分 GC 的工作,应用线程之间也存在由 GC 引入的数据竞争关系。 “内存屏障”机制用于解决 GC 线程与仓颉线程的数据竞争。在并发 GC 中,最广泛存在的数据竞争是 GC 线程与应用线程的竞争。比如当 GC 线程想要把某个活对象移动到新地址,而几乎同时业务线程想要访问这个对象。内存屏障用于在应用线程访问内存时,可以跟 GC 线程采取协调一致的操作。
减少内存碎片和内存峰值
仓颉 GC 采用的内存整理技术是当前流行的用于内存回收最前沿的技术之一(当然其算法实现的复杂度也相对增加)。相比于现有的 Mark-Sweep 算法,内存整理技术可以把分散的活对象搬移到更紧凑的内存布局里,大幅地减少了内存碎片。相比于复制算法把 from-space 中的活对象全部复制到 to-space 后,才能释放 from-space 的内存,内存整理技术可以一边搬移活对象、一边释放已经完成整理的内存块,消除复制 GC 带来的内存尖峰。
在仓颉的全并发标记整理 GC 中,仓颉堆内存被划分为小块连续内存,称为 region. from-region 是 from-space 中的一个 region,to-region 是 to-space 中的一个 region. 在堆内存整理过程中,from-region 中的活对象都被搬移到合适的 to-region 里,构成更紧凑的内存布局。搬移完成后,这个 from-region 即可被释放用于分配新对象。在内存压力大的情况下,from-region 和 to-region 在内存空间上可以重叠,进一步降低内存峰值。
极快的对象分配速度
得益于仓颉 GC 采用的对象搬移技术回收内存,仓颉运行时实现了基于指针跳动(bumping-pointer)技术的对象分配方式,这是现有先进的内存分配技术,平均约 10 个时钟周期就可以完成一次内存分配。
优化 GC 开销
仓颉的全并发内存整理算法采用指针标记来加速识别访存操作中的快速路径。指针标记把仓颉对象中的引用成员分为三种状态:(1) 未标记;(2) 已标记且是在当前 GC 过程中被标记,称为”current pointer”;(3) 已标记且是在上一次 GC 过程中被标记,称为”old pointer。未被标记的指针就是仓颉对象的真实地址,可以直接用于访存,这是访存的快速路径。old pointer 是来自于上一次 GC,还未修复的旧指针,需要在 enum 和 trace 阶段由 GC 线程或内存屏障查询转发表后更新。current pointer 是在当前 GC 的 enum 和 trace 阶段被标记,用于指示哪些对象可能被移动。当内存屏障访问到被标记的 old pointer 时,需要查询转发表获取新地址。当内存屏障访问到被标记的 current pointer 时,需要根据当前的 GC 状态进一步判断该对象是否已经被转移,如果已经被转移,则查询转发表获取新地址,否则,内存屏障需要把该对象转移到相应的 to-region,并且更新被标记的指针。
在仓颉的全并发内存整理算法里,被标记的指针是按需用 lazy 的方式被更新,只有在被内存屏障访问时,被标记的指针才会被更新。如果未被访问到,被标记的指针会被保留到下一次 GC 的 enum 和 trace 阶段更新。这个策略可以显著减少 GC 过程的持续时间。
适配值类型
如前述,在仓颉语言中引入值类型赋予开发者更优越的内存和性能开发选择,但也使 GC 的实现更加复杂。对于纯引用的编程语言(如 Java、JavaScript、Kotlin),除基础类型外,其它类型都是引用类型,这个模型对于 GC 算法更加友好。值类型在两个方面使 GC 算法变得更加复杂:(1) 值类型的数据可能是其它数据的成员,也可能是独立的全局或局部变量,两种情况下的数据处于不同的内存区域,但是对于值类型的成员方法而言,二者必须具有统一的行为定义。(2) 值类型的数据是以内嵌的形式从属于其它值类型或者引用类型,内嵌改变了内存布局。在支持对象搬移的仓颉 GC 实现过程中,结合值类型特性,GC 的工程复杂度大幅增加了。考虑到值类型带给开发者更强大更便利的表达能力、更优越的应用性能和内存表现,在仓颉语言实现上的内部复杂度增加是物有所值的。