静态编译优化
仓颉编译采用模块化编译,编译流程间通过 IR 作为载体,不同编译优化之间,做到互相不影响。对于编译优化的适配,编译流程的调整,拥有更高的自由度。 仓颉语言使用静态编译手段,将仓颉程序、核心库代码等编译成机器代码,加速程序运行速度。
GC 相关优化
仓颉静态编译中,添加了许多运行时联合优化。例如对于堆上对象读写的优化、堆对象创建的优化、以及堆内存管理信号机制的优化等。静态分析和运行时的联合优化,加快了仓颉程序在对象的创建、读写、成员函数调用等方面的运行速度。
仓颉静态后端在对象读写时,通过向量化访问,保证数据读写、运算速率,尽量减少函数调用对性能的影响。对堆对象的活跃作用域的分析,也保证了静态后端能够对堆对象的分配地址拥有决定权,无论在堆、栈或常量区,静态后端能根据对象特性来进行分配优化。
仓颉对于栈上引用的精确记录,能够加快 GC 信息采集速度。精确栈对象的记录,减少了垃圾回收根集合的数量,避免了对象指针的冗余地址判断。在扫描和 fix 阶段,保证了 GC 程序高效运行。
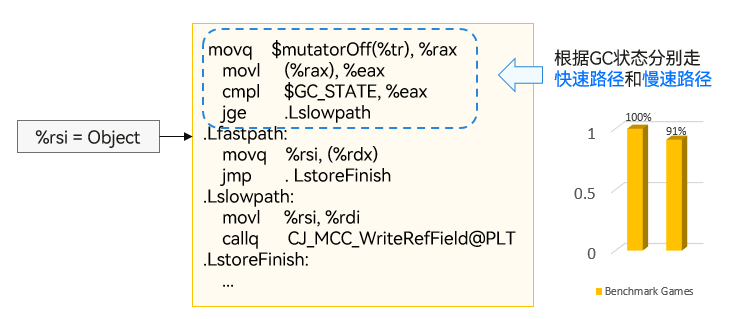
结合 GC 功能,仓颉语言对于对象的创建、读写上进行了 fastPath 优化。如下图所示,在编译访存操作时,生成快速路径和高效判断快速路径的指令,减少性能开销。
逃逸分析
仓颉语言在做全局分析优化时,增加了引用的逃逸分析。对于引用的类型,仓颉语言分析该引用的生命周期,对于未逃逸出其所在函数的引用,可以采用栈上分配优化。如下代码所示,其中包含了部分逃逸分析结果。
class B {}
class A {
var a: Int64 = 0
var b: B = B()
}
var ga: A = A()
func test1(a: A) {
a.a = 10
}
func test2(a: A) {
ga = a // escape to global
}
func test3(a: A, b: B) {
a.b = b
}
main() {
var instance: A = A() // alloca on stack, not escape out this func
instance.a = 10
var instance1: A = A() // alloca on stack, test1 not escape param a
test1(instance1)
var instance2: A = A() // gc malloc in heap, test2 escapa param a
test2(instance2)
var instance3: B = B() // alloca on stack, instance3 store into instance1, but instance1 not escaped.
test3(instance1, instance3)
var instance4: B = B() // gc malloc in heap, instance4 store int instance2 and instance2 escaped to global.
test3(instance2, instance4)
}
通过栈上分配优化,可以直接缩减自动管理内存的 GC 压力,减少堆上分配内存和频率,降低垃圾回收频率。对于堆上内存的读写屏障,也会因为栈上分配从而变成直接的数据存取,加快了内存访问速度。对象栈上分配后,对于栈上内存,又可以额外采用例如 SROA,DSE 等优化措施,减少内存读写次数。
类型分析/去虚化
仓颉语言支持全局类型静态分析和结合 Profile 的类型预测。仓颉语言支持类型继承,支持虚函数、接口函数调用,对于虚函数、接口函数的调用,相比较 Direct Call 增加了额外的查找、访问开销。
对于全局引用、局部引用、过程间引用等,通过静态分析的方式,仓颉语言将部分虚函数调用改写为 Direct Call,加速函数调用,提升函数内联等优化机会。
在 PGO 模式下,仓颉语言支持虚函数调用的类型、数量统计,通过 Profile 信息捕捉到的热类型、热调用部分,通过保守去虚化的方式,加速函数调用和程序执行。
