Lock-Free Concurrent Object
In concurrency scenarios where multiple threads share the same memory, programmers must control the sequence in which different threads access the same memory unit to prevent data races. Generally, features such as mutex are provided in programming languages to enable multiple processes to access the same memory simultaneously.
However, it is complex for programmers to control the access of threads to the shared memory which may cause poor concurrency performance.

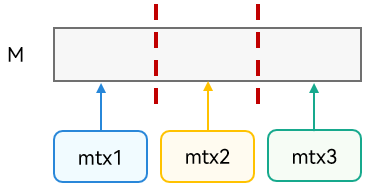
As shown in the preceding figure, a memory block M is shared by multiple threads whose concurrent accesses to the memory block M are synchronized by a mutex. As a result, the optimal development efficiency and running performance are not achieved.
Is it possible to divide the memory block M into multiple areas and lock it in a finer granularity for better performance and enable automatic protection of shared memory by using a mutex to make multithreaded programming as simple as single-threaded programming?
The following figure shows fine-grained concurrency control. The memory block M is divided into multiple areas, and different threads can concurrently access different areas. However, the fine-grained concurrency algorithm is complex. In actual scenarios, the memory block M may represent a data structure. It is not easy to perform fine-grained concurrency control on a complex data structure, and concurrency problems, such as data races or the lack of atomicity in concurrent programming, are likely to occur.
To solve those problems, Cangjie provides concurrent objects implemented based on the fine-grained concurrency algorithm. Users can call the APIs of the concurrent objects to control the concurrent access to the shared memory by multiple threads. In this way, the following functions are implemented:
- Lock-free programming. Users can call APIs to implement efficient concurrent access to the shared memory by multiple threads.
- Concurrency security assurance. The APIs provided by the Cangjie concurrent objects eliminate data races and ensure that the call and execution of all core APIs are completed without interruption.
- Better performance. The fine-grained concurrency algorithm is used to design the Cangjie concurrent objects.
- Atomicity of concurrent programming. The core APIs provided by the Cangjie concurrent objects are "atomic". That is, from users' perspective, the call and execution of these APIs are not interrupted by other threads.
The following table lists the types of concurrent objects shared by multiple threads provided by Cangjie to guarantee concurrency security and performance.
| Type | Data Structure |
|---|---|
| Atomic Integer | AtomicInt8, AtomicInt16, AtomicInt32, AtomicInt64, AtomicUInt8, AtomicUInt16, AtomicUInt32, and AtomicUInt64 |
| Atomic Boolean | AtomicBool |
| Atomic Reference | AtomicReference and AtomicOptionReference |
| Concurrent Hash Map | ConcurrentHashMap |
| Concurrent Queue | BlockingQueue, ArrayBlockingQueue, and NonBlockingQueue |
- Concurrency security
In concurrency scenarios, data races do not occur when a user uses an atom type and calls a concurrent data structure API to operate objects shared by multiple threads. Atom types provide users with operations of AtomicInteger, AtomicBoolean, and AtomicReference in concurrency scenarios. The call and execution of the core APIs of a concurrent data structure are not interrupted by other threads, such as the put method for key-value pair insertion, the remove method for key-value pair deletion, and the replace method for key-value pair replacement in ConcurrentHashMap. In concurrency scenarios, the call and execution of these operations are not interrupted by other threads.
- Better concurrency performance
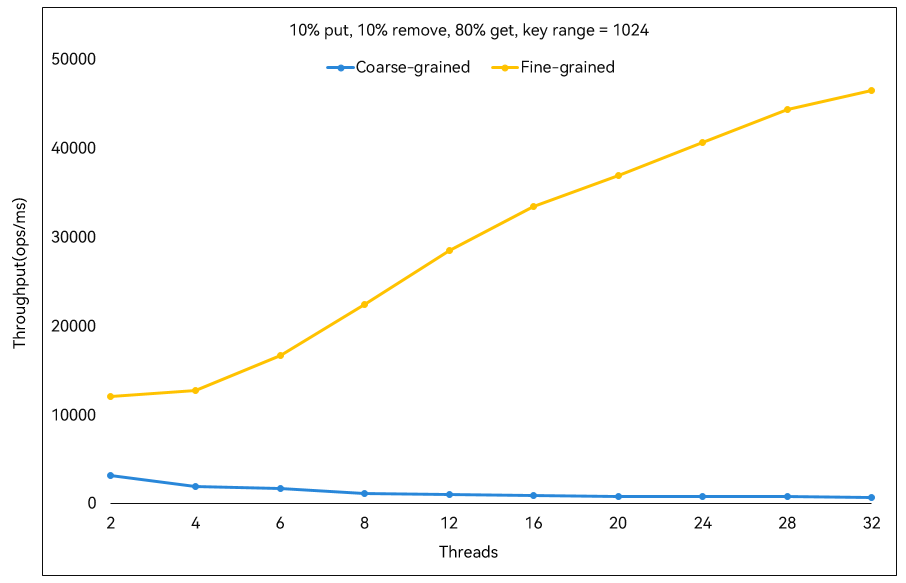
Concurrent Hash Map and Concurrent Queue are implemented based on the fine-grained concurrency algorithm described above. The following figure shows the performance comparison between ConcurrentHashMap and the using of a mutex to control concurrent access to HashMap by multiple threads (that is, coarse-grained concurrency control). The horizontal coordinate indicates the number of threads and the vertical coordinate indicates the number of ConcurrentHashMap operations completed per millisecond. In the ConcurrentHashMap operations, the put, remove, and get methods account for 10%, 10%, and 80% respectively. The yellow line indicates the test data of the Cangjie ConcurrentHashMap, and the blue line indicates the test data of the coarse-grained concurrency control method. It can be seen that the performance of the Cangjie ConcurrentHashMap using the fine-grained concurrency algorithm is obviously better than that of the coarse-grained concurrency control method, and that the performance is improved as the number of threads increases.
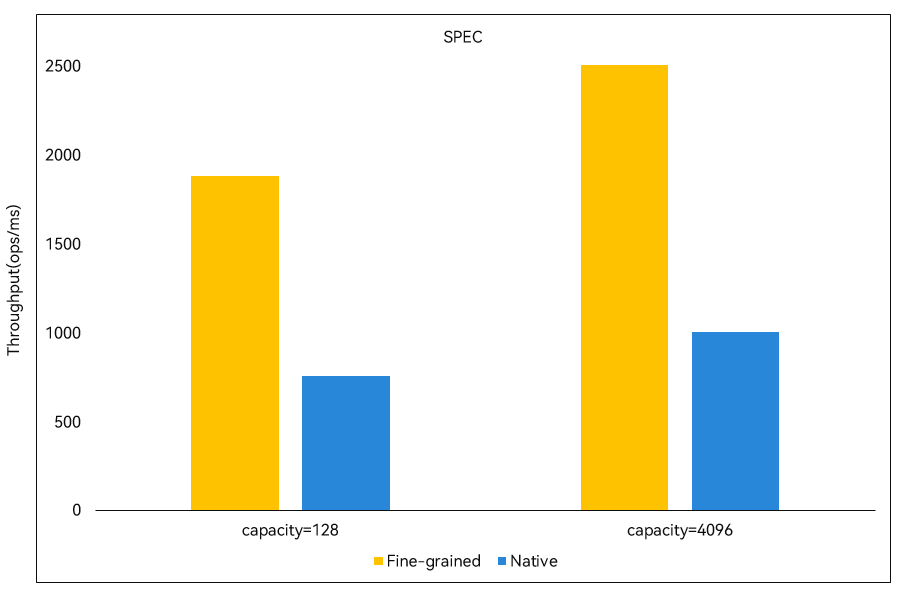
The following figure shows the performance comparison between the Cangjie BlockingQueue and the using of a mutex to control concurrent access to a queue by multiple threads (that is, coarse-grained concurrency control) in the single-producer and single-consumer scenario. We performed the comparison with queue capacity of 128 and 4096, respectively. The vertical coordinate indicates the number of elements enqueued or dequeued per millisecond. The performance of the Cangjie BlockingQueue is obviously better than that of the coarse-grained concurrency control method.